Read (Almost) Any Document in Java




A Jungle of Formats
Have you ever wanted to read a Microsoft Word document from your Java program? What about a PDF file? Or maybe a book published in the EPUB format? If so you will undoubtedly have decided that you don’t want to unpick the format yourself just to get at the text. There are some great Open Source parsers available for these and other formats but even so you need to find them all and work with the different APIs. Add to that the problem of selecting the right parser for the right file and the task of extracting plain text from a document can become a headache.
Apache Tika
Apache Tika solves this problem and lets you get at the text in document files easily. Not only that but it can automatically determine the format of a document and choose the appropriate parser for you. You can feed it a Microsoft Word document or a PDF file and read the text back without ever having to specify the document format. In fact it will handle over a thousand different file types and all of this can be done using the same Java API. I think it goes without saying that this Open Source project makes reading text files much easier.
VocabHunter
VocabHunter is an Open Source project that uses Apache Tika to read document files. It is a Java desktop application designed to help learners of foreign languages. The central idea is to enable someone to identify the most important vocabulary to study in a book before they start reading the book. A user might, for example, make up flashcards for the significant new vocabulary in a book with the help of the information provided by VocabHunter. Of course, different users will have books in different formats and this is where Apache Tika comes in. Thanks to Apache Tika, VocabHunter is able to offer the ability to read documents of many different types seamlessly to the user. You can see the system in action here:
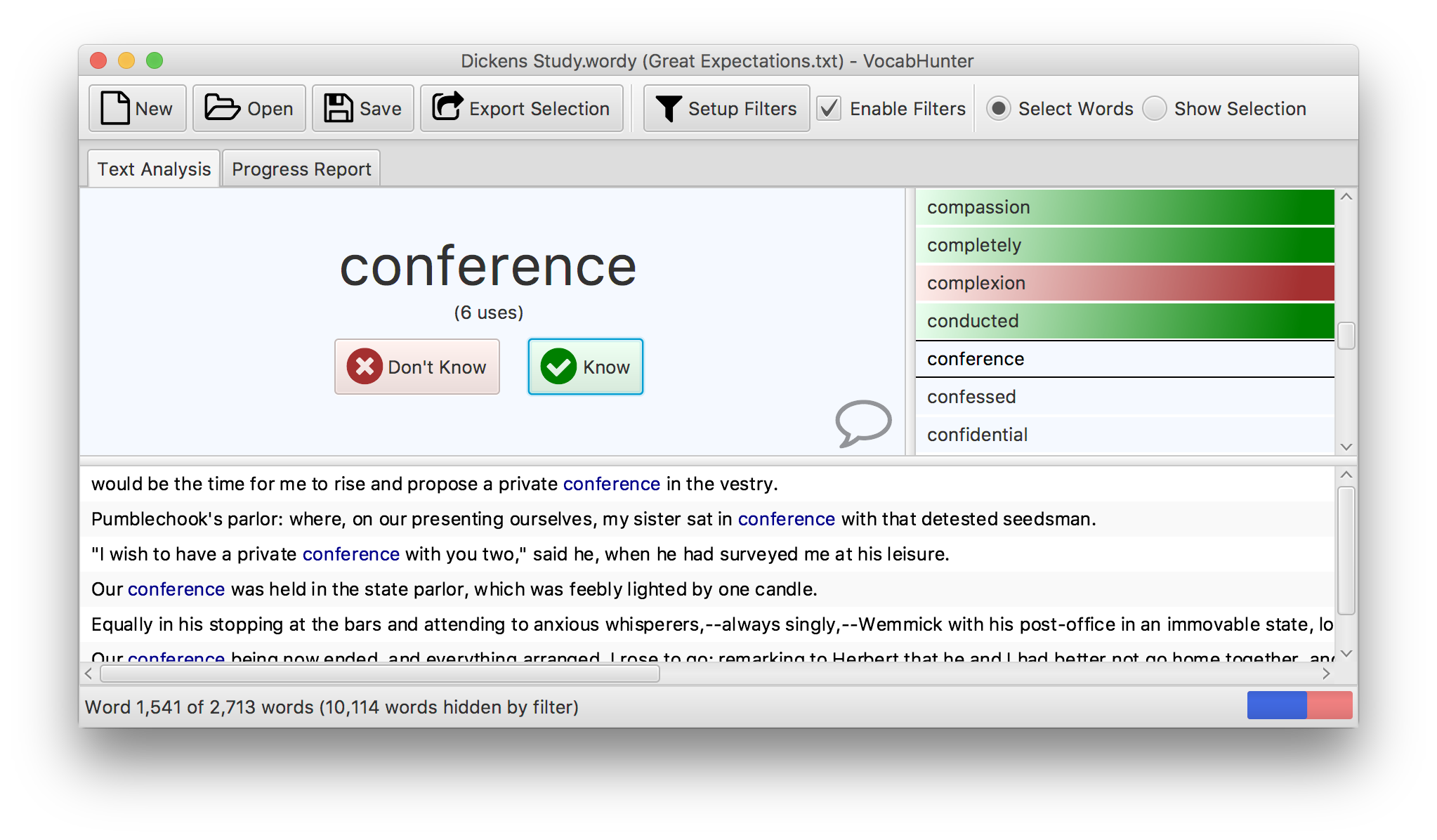
All of the source code for VocabHunter is available on GitHub. In the following section I show how the Apache Tika API is used in VocabHunter.
Reading Documents
Apache Tika offers a simple API for the basic use case where you want to read all of the text from a document. Using this API there is no need to specify the format or to select a parser as Tika will handle this for you. You can see it in use in VocabHunter in the class TikaTool. The code that extracts the text from a document is as follows:
Metadata metadata = new Metadata();
try (InputStream in = TikaInputStream.get(file, metadata)) {
Tika tika = new Tika();
return tika.parseToString(in, metadata, -1);
} catch (IOException | TikaException e) {
throw new VocabHunterException(
String.format("Unable to read file '%s'", file), e);
}
As you can see, with a few short lines of code, the problem is solved. Since VocabHunter is a desktop application reading documents for just one user, there is no problem with reading an entire text file into memory. For this reason there is no maximum size specified (the -1 above does this) but if you plan to read arbitrary files from unknown sources on a server it would be wise to set a maximum size.
Tika is capable of much more than this and you can also use it for other tasks including language detection. I hope that the above serves to show how useful it has been in my work on VocabHunter but to find out more, go to the Apache Tika website.
Final Words
Apache Tika has proved to be a really valuable tool in the VocabHunter project. I encourage you to investigate it further and see if you can make use of it in your project. Also, feel free to fork VocabHunter on GitHub and play around with the source code to see one way that Tika can be used. It is all Open Source and I hope you find it interesting. I welcome code contributions and feedback.
Related Articles
- How JavaFX was used to build a desktop application (King Tech Blog)
- Migrating to JUnit 5
- Installable Java Apps with jpackage
- Building a JavaFX Search Bar
- Dependency Injection in JavaFX
- User Interface Testing with TestFX
- VocabHunter – A tool for learners of foreign languages (King Tech Blog)
- Open Source & Secret Santa with Santulator (King Tech Blog)